
概要
配列の扱い方について学んでいきましょう。
配列は、同一の型の値を複数持つことができるデータ構造です。
・int型の配列だったら、int(数値)を複数個持っている。
・String型の配列だったら、String(文字列)を複数持っている。
というものです。
初期化
基本構文
型または変数名の後に[]を付けます。
代入する際は、配列数を指定します。指定しないとコンパイルエラーになります。
|
1 2 3 4 5 |
// 基本構文 int[] array = new int[3]; // 型に[]を付ける String str[] = new String[3]; // 変数名に[]をつける // コンパイルエラー Object[] obj = new Object[]; // 初期化では配列数を指定する必要がある |
(コラム)
[](角カッコ)は、型の隣につけるのが一般的かなと思います。
ちなみにGoogle Style(Googleのコーディング規約)でも、型の隣に[]をつけるように明示しています。
The square brackets form a part of the type, not the variable: String[] args, not String args[]
4.8.3.2 C言語形式での配列宣言は禁止する
角括弧は型の一部であり、変数ではありません。String[] argsであり、String args []ではありません。
初期化子
初期化子とは、配列の次元数と値の代入を同時に行う方法です。
|
1 2 3 |
// 初期化子 int[] values = {1, 2, 3}; // 次元数1つ、要素数3つのint値を初期化 String[] titles = {}; // 空の配列 |
次元
次元とは、配列の単位です。
配列とは複数の値を持つことができるデータ構造でしたよね。
以降で図解も含めながら理解を深めていきましょう。
一次元配列
[]が1つの配列です。
値が箱のような区切り毎に入っているイメージです。

※indexについては後で説明致します。
ここでは、配列の要素にアクセスするための番号であるという認識でOKです。
多次元配列
多次元配列とは、配列の中にある配列です。
具体的に、二次元配列・三次元配列を見ていきましょう。
二次元配列
[]が2つの配列です。
多次元配列になると、値を持っているのは最後の次元(ここでは2次元目)です。
1次元目は2次元目をまとめる単位になっています。

三次元配列
[]が3つの配列です。
[]が増えるごとにデータ構造が複雑になるので、三次元以上の多次元配列を使うことは無いと思います。
三次元配列になると、配列の構造がちょっとわかりずらくなるので以下の図では表とコードを対応付けてみました。
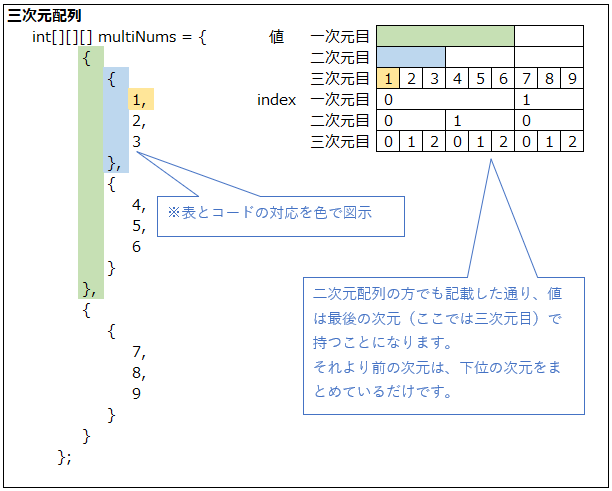
インデックス
配列の要素を参照するための番号です。
0から振られており、要素の数だけあります。
(0から振られる関係上、最後のインデックス番号は要素数-1になります)
|
1 2 3 4 5 6 7 8 9 10 |
// インデックス int[] num = {1, 2, 3}; for(int index=0; index < num.length; index++) { System.out.println("index = " + index + " , num = " + num[index]); } // 実行結果 index = 0 , num = 1 index = 1 , num = 2 index = 2 , num = 3 |
例外
配列のインデックス番号の範囲外を指定すると、例外(ArrayIndexOutOfBoundsException)がスローされます。
|
1 2 3 4 5 6 7 |
// 例外 int[] exception = {1, 2, 3}; System.out.println("index = " + 3 + " , num = " + num[3]); // 実行結果 Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: Index 3 out of bounds for length 3 at introduction/array.ArrayMain.main(ArrayMain.java:46) |
コピー
参照コピー
配列は参照型オブジェクトなので、単純な代入は参照先をコピーするだけになります。
そのため、コピー先を変更すると、コピー元も変更されます。
|
1 2 3 4 5 6 7 8 9 10 11 |
// 参照コピー int[] source = {1, 2, 3}; int[] copied = source; System.out.println("index = " + 0 + " , source = " + source[0]); copied[0] = 10; // コピー先のindex0の値を変更(1 -> 10) System.out.println("index = " + 0 + " , source = " + source[0]); // 実行結果 index = 0 , source = 1 index = 0 , source = 10 // コピー先(copied)の変更がコピー元(source)に影響している |
参照型については、以下を参照下さい。
⇒参照型とは?
cloneメソッド
プリミティブ型の1次元配列
同じ値をもった配列が生成されます。
参照先をコピーしているわけではなく、別のインスタンスを参照しているため、コピー先の変更はコピー元に影響を与えません。
参照先が異なることは、==による等価判定でfalseになることでも確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// cloneメソッド int[] source = {1, 2, 3}; int[] copied = source.clone(); System.out.println("index = " + 0 + " , source = " + source[0]); copied[0] = 10; // コピー先のindex0の値を変更(1 -> 10) System.out.println("index = " + 0 + " , source = " + source[0]); // 実行結果 index = 0 , source = 1 index = 0 , source = 1 // コピー先(copied)の変更はコピー元(source)に影響しない // 参照先の評価 System.out.println(source == copied); // false |
プリミティブ型の多次元配列
(2021年5月25日追記)
1次元配列においては誤りではありませんが、多次元配列においては2次元目以降がコピー元と同じなので参照コピーと変わらないことを私が理解したため、追記致します。
実際、公式ページでもcloneメソッドはシャロ―・コピーであると記述されています。
|
1 2 3 4 5 6 7 8 9 10 11 |
// cloneメソッド int[][][] source = {{{1, 2, 3},{4, 5, 6}},{{1, 2, 3},{4, 5, 6}}}; int[][][] copied = source.clone(); System.out.println("source = " + source + " , copied = " + copied); System.out.println("source[0] = " + source[0] + " , copied[0] = " + copied[0]); System.out.println("source[0][0] = " + source[0][0] + " , copied[0][0] = " + copied[0][0]); // 実行結果 source = [[[I@1d251891 , copied = [[[I@48140564 source[0] = [[I@58ceff1 , copied[0] = [[I@58ceff1 source[0][0] = [I@7c30a502 , copied[0][0] = [I@7c30a502 |
多次元配列をcloneした結果を確認すると、変数の参照先は異なるものが生成されていますが、配列の中身は同じものを参照しています。
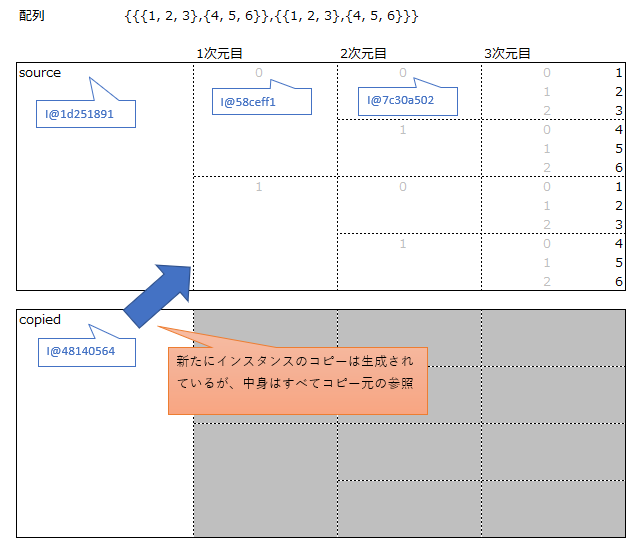
つまり、多次元のプリミティブ型配列は、参照する入り口が変わっただけで、中身の参照先は変わっていないので値を書き換えるとコピー元にも影響します。
まとめ
- 配列は同一型の複数の値を扱うデータ構造である。
- 配列は初期化してから使う必要がある。
- 多次元配列とは配列の中にある配列のことである。
- インデックスは配列を参照するための番号である。
- コピーには参照コピーとcloneメソッドによる値の複製がある。









コメント